Overview
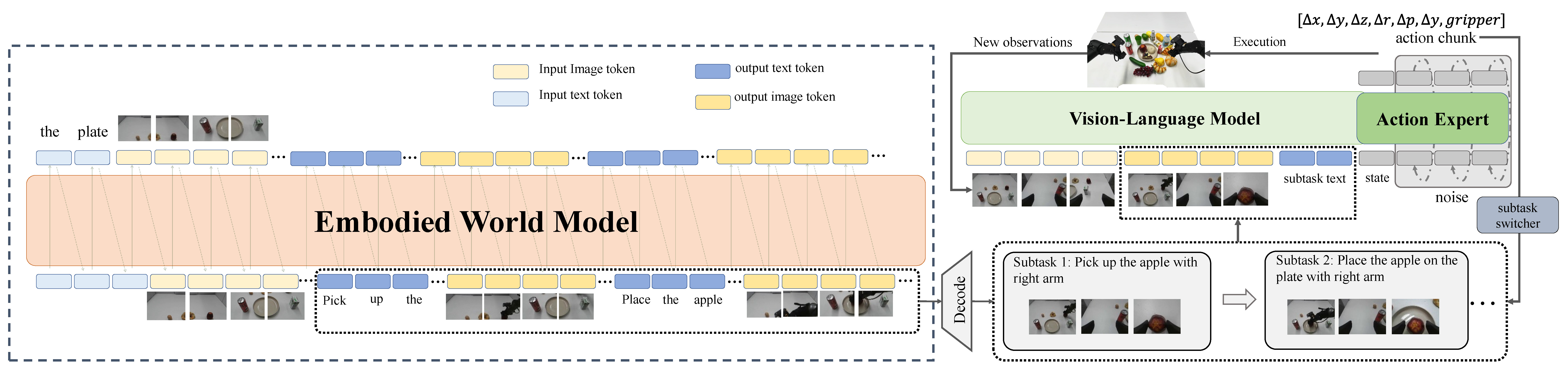
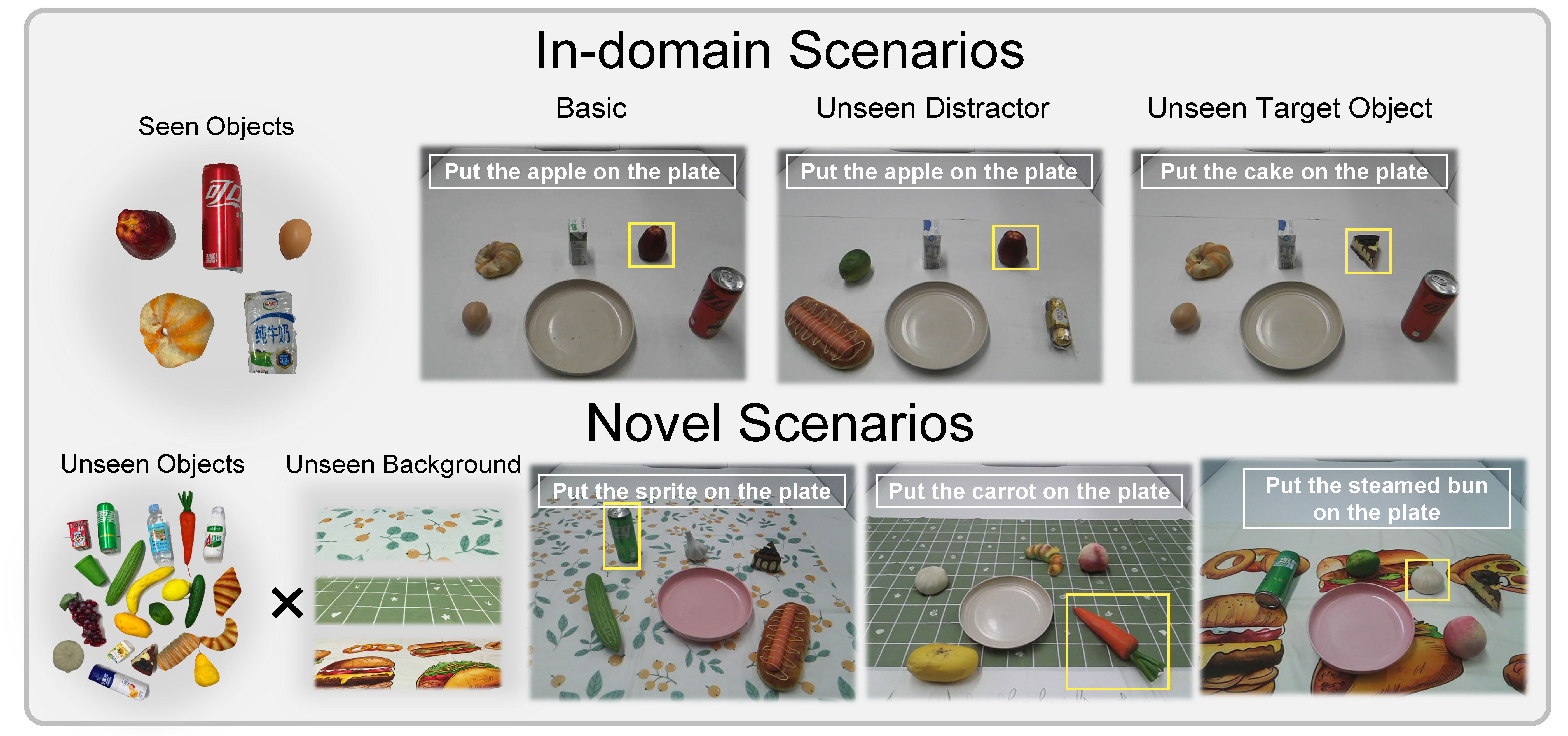
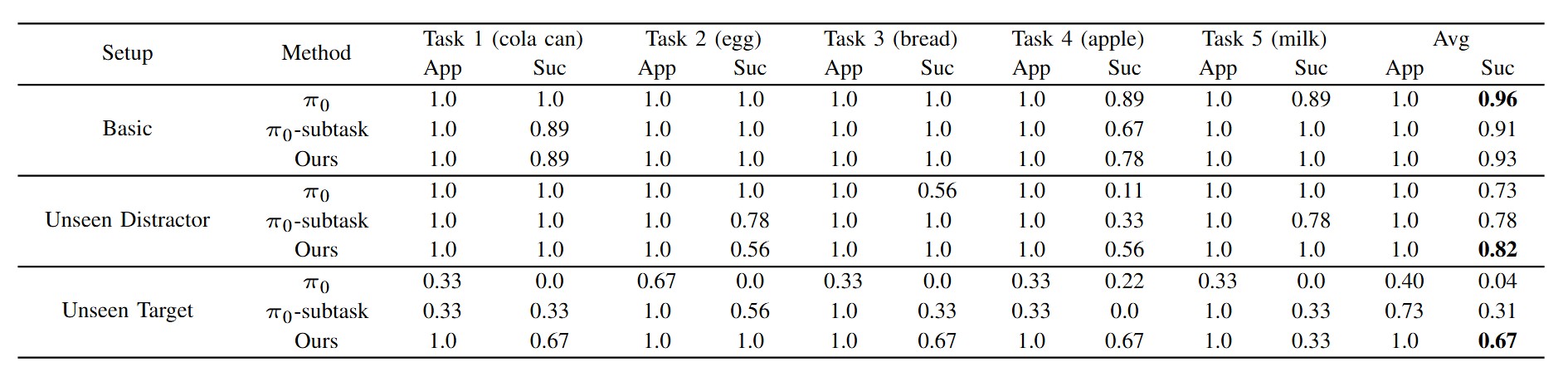
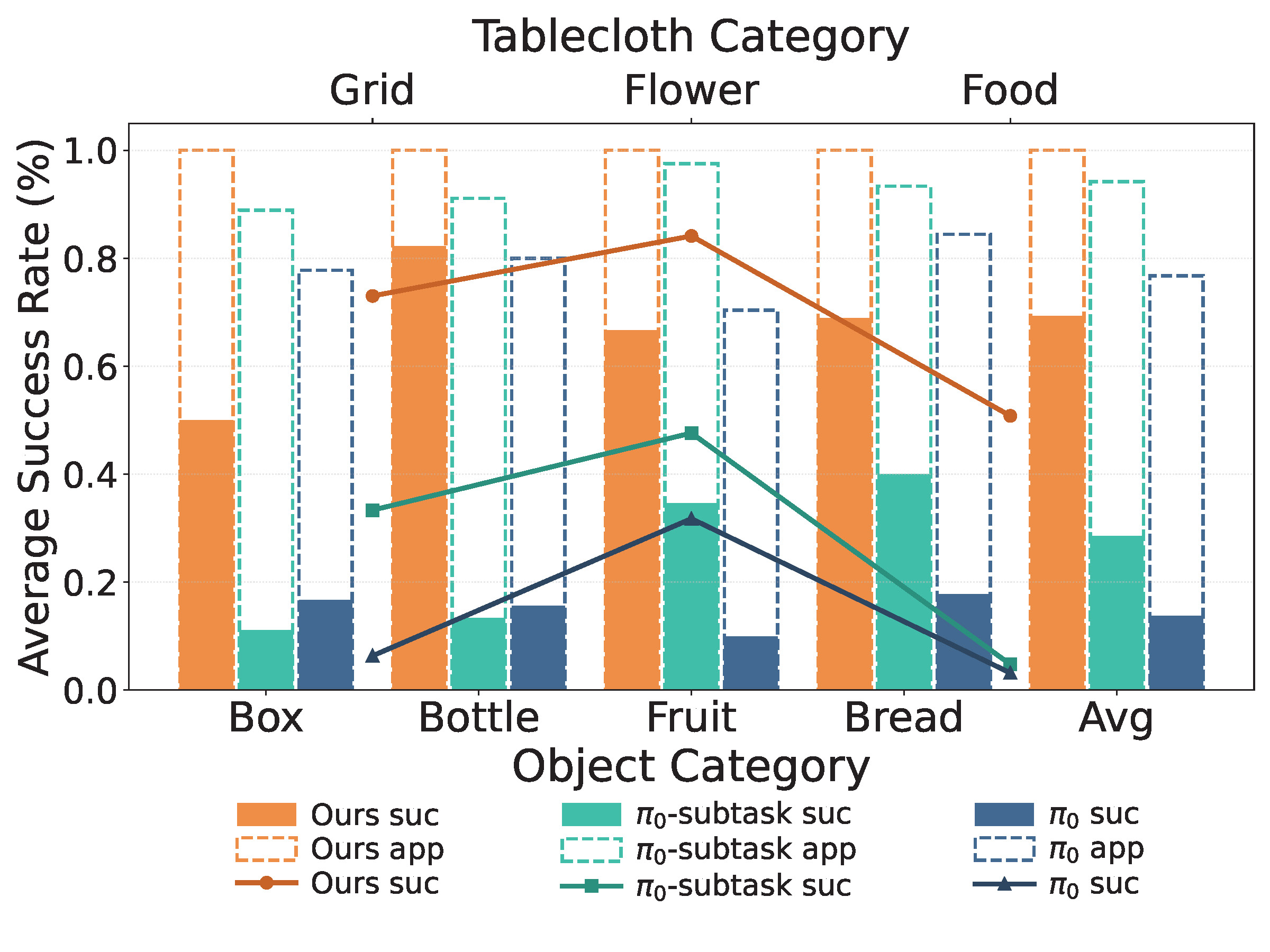
We introduce VISTA, a hierarchical Vision-Language-Action framework that leverages the generalization of large-scale pre-trained world model for robust and generalizable Visual Subgoal TAsk decomposition. Our hierarchical framework consists of a world model as the high-level planner and a VLA as the low-level executor. The high-level world model first divides manipulation tasks into subtask sequences with goal images, and the low-level policy follows the textual and visual guidance to generate action sequences. Compared to raw textual goal specification, these synthesized goal images provide visually and physically grounded details for low-level policies, making it feasible to generalize across unseen objects and novel scenarios.